|
| 1 | +--- |
| 2 | +title: "Databricks开源限流方案,抛弃redis,性能提升10倍" |
| 3 | +source: "https://mp.weixin.qq.com/s/VLkB6OWtLa_bn9OBeQvVHQ?from=industrynews&color_scheme=light#rd" |
| 4 | +author: |
| 5 | + - "[[winkrun]]" |
| 6 | +published: |
| 7 | +created: 2025-10-11 |
| 8 | +description: |
| 9 | +tags: |
| 10 | + - "clippings" |
| 11 | +--- |
| 12 | +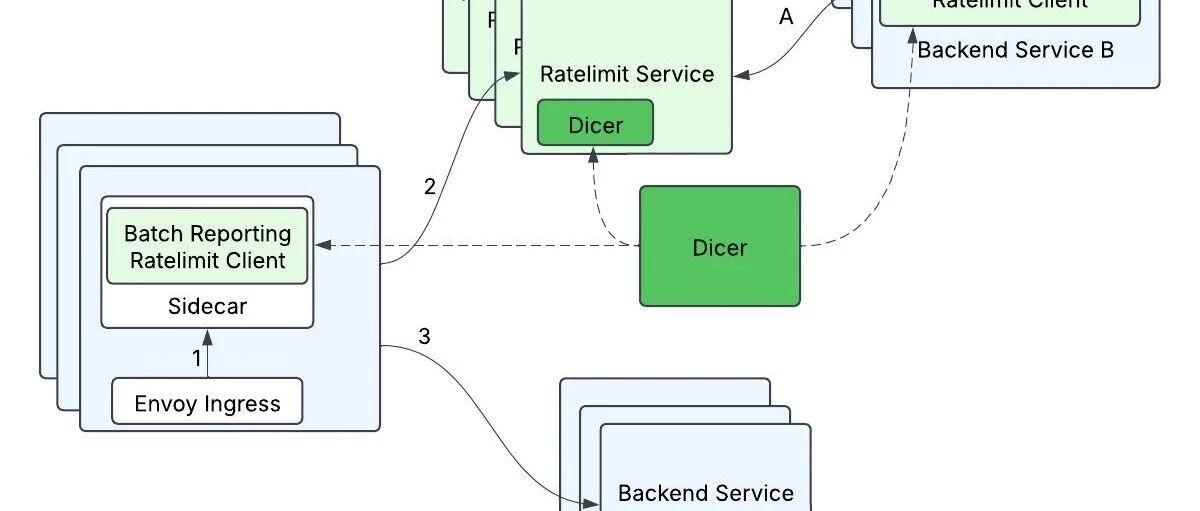 |
| 13 | + |
| 14 | +原创 winkrun [AI工程化](https://mp.weixin.qq.com/s/) *2025年10月05日 05:33* |
| 15 | + |
| 16 | +Databricks 最近开源了他们的高性能限流系统设计,这个方案跳出了"限流必须用 Redis"的思维定势,通过内存分片和批量上报机制,实现了 10 倍的性能提升。 |
| 17 | + |
| 18 | +## 抛弃redis |
| 19 | + |
| 20 | +2023 年初,Databricks 的限流系统还是个标准配置:Envoy 网关调用限流服务,后端用单个 Redis 实例存储计数。随着实时模型服务等高 QPS 场景的引入,这套架构开始力不从心。P99 延迟达到 10-20ms,而且 Redis 成了整个系统的瓶颈和单点故障。 |
| 21 | + |
| 22 | +Databricks 的工程师们意识到一个关键事实:大部分限流都是按秒计算的,这些计数本质上是临时数据。既然不需要持久化,为什么要用 Redis? |
| 23 | + |
| 24 | +## 两个关键设计 |
| 25 | + |
| 26 | +他们用了两个关键设计来重构整个系统:内存分片和客户端批量报告。 |
| 27 | + |
| 28 | +### 内存分片:分而治之 |
| 29 | + |
| 30 | +传统的集中式限流有个天然瓶颈 - 所有请求都要经过同一个 Redis 实例。内存分片的思路是把限流计数分散到多个节点上: |
| 31 | + |
| 32 | +``` |
| 33 | +传统方式: |
| 34 | +所有请求 → Redis(单点) → 返回结果 |
| 35 | +
|
| 36 | +内存分片方式: |
| 37 | +用户A的请求 → 节点1(负责用户A-F) |
| 38 | +用户M的请求 → 节点2(负责用户G-M) |
| 39 | +用户Z的请求 → 节点3(负责用户N-Z) |
| 40 | +``` |
| 41 | + |
| 42 | +通过引入 Dicer 自动分片技术,相同的限流键总是被路由到同一个节点。每个节点在自己的内存里独立计数,完全不需要跨节点同步。需要更大容量时,加节点就行。 |
| 43 | + |
| 44 | +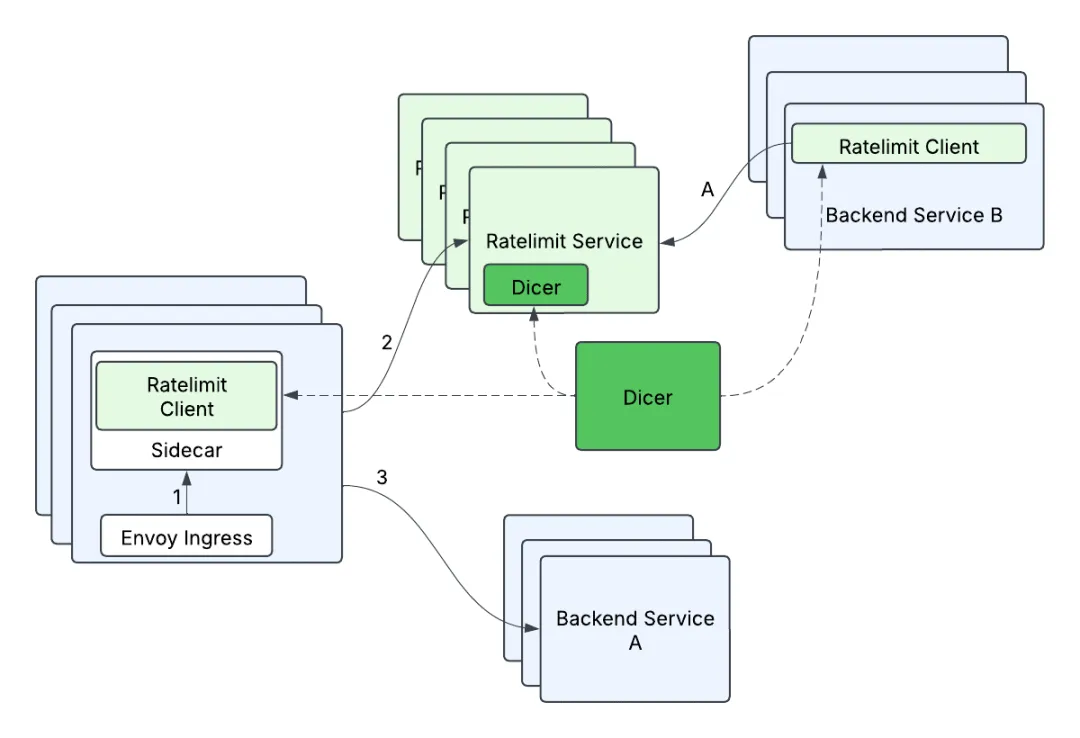 |
| 45 | + |
| 46 | +### 批量报告:化零为整 |
| 47 | + |
| 48 | +客户端批量报告则从另一个角度优化性能。传统方式下,每个请求都要查询限流服务并等待响应,这意味着大量的网络往返。 |
| 49 | + |
| 50 | +新方案采用了完全不同的思路: |
| 51 | + |
| 52 | +``` |
| 53 | +1. 客户端默认放行请求(乐观限流) |
| 54 | +2. 本地记录放行和拒绝的数量 |
| 55 | +3. 每 100ms 批量上报:{API_A: 45次, API_B: 55次} |
| 56 | +4. 服务器返回哪些需要限流,以及限流比例 |
| 57 | +5. 客户端根据指令调整后续的限流行为 |
| 58 | +``` |
| 59 | + |
| 60 | +这种设计把原本的 N 次网络往返减少到 1 次,而且是异步的,不阻塞请求处理。限流判断的延迟因此接近于零。 |
| 61 | + |
| 62 | +### 两者的巧妙结合 |
| 63 | + |
| 64 | +这两个设计相互补充,解决了不同维度的问题: |
| 65 | + |
| 66 | +- **内存分片** 解决了服务端的扩展性,打破了集中式瓶颈 |
| 67 | +- **批量报告** 解决了客户端的性能问题,消除了同步等待 |
| 68 | + |
| 69 | +更妙的是,批量报告时会按目标节点分组,避免了扇出爆炸: |
| 70 | + |
| 71 | +``` |
| 72 | +100个请求按目标节点分组: |
| 73 | +- 节点1:35个请求合并成1个批量请求 |
| 74 | +- 节点2:40个请求合并成1个批量请求 |
| 75 | +- 节点3:25个请求合并成1个批量请求 |
| 76 | +``` |
| 77 | + |
| 78 | +## 令牌桶:更智能的限流算法 |
| 79 | + |
| 80 | +在实现内存限流后,他们还把限流算法从固定窗口改成了令牌桶。固定窗口算法有个问题:每个时间窗口开始时计数器都会重置,可能导致窗口边界的流量突发。 |
| 81 | + |
| 82 | +令牌桶算法可以"记住"超限情况。如果某个客户在上一秒发了 150% 的请求,令牌桶会变成负数,下一秒需要等桶慢慢恢复才能继续。这种连续性让限流更加平滑和准确。 |
| 83 | + |
| 84 | +## 工程挑战与解决 |
| 85 | + |
| 86 | +理想很美好,但实现过程充满挑战: |
| 87 | + |
| 88 | +**精度控制** :批量上报的异步特性可能导致超限。他们用了三重保护:基于历史数据的拒绝率预测、客户端本地限流器、以及令牌桶算法的连续性。 |
| 89 | + |
| 90 | +**在线迁移** :最棘手的是如何在不停服的情况下完成改造。他们采用了渐进式方案,先给 Envoy 加 sidecar,用 Lua 脚本优化 Redis 批量写入,最后才切换到完全的内存方案。 |
| 91 | + |
| 92 | +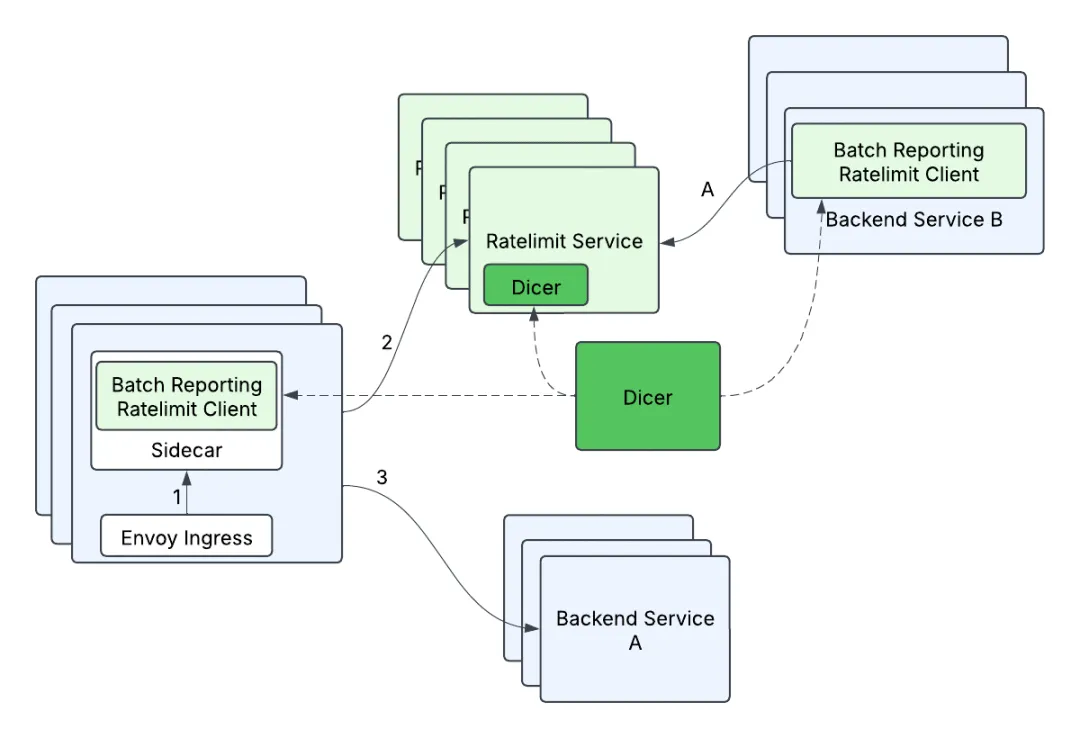 |
| 93 | + |
| 94 | +## 一致性的权衡 |
| 95 | + |
| 96 | +这个方案在分布式一致性上做了明智的权衡。通过 Dicer 保证同一个限流键的所有请求都路由到同一实例,避免了分布式计数。批量上报提供了最终一致性 - 可能有 100ms 的延迟,但最终会收敛到正确状态。 |
| 97 | + |
| 98 | +这种权衡对大多数场景是合理的。API 限流、资源保护这类场景,5% 的短暂超限通常在系统容量范围内。但对于金融交易、库存扣减这类需要强一致性的场景,还是需要传统方案。 |
| 99 | + |
| 100 | +## 改造成果 |
| 101 | + |
| 102 | +改造后的系统取得了显著成效: |
| 103 | + |
| 104 | +- 尾部延迟改善高达 10 倍 |
| 105 | +- 彻底解决了 Redis 单点故障问题 |
| 106 | +- 内部服务调用限流时零延迟 |
| 107 | +- 系统可以通过加节点线性扩展 |
| 108 | + |
| 109 | +从方案可以看出,没有什么奇技淫巧,Databricks没有试图用一个复杂的方案解决所有问题,也没有墨守固定的模式,而是用内存分片和批量报告两个相对独立的机制,分别解决服务端扩展性和客户端性能问题,没有一味追求强一致性,进而换来整体性能的巨大提升。 |
| 110 | + |
| 111 | +关注公众号回复“进群”入群讨论。 |
| 112 | + |
| 113 | +继续滑动看下一个 |
| 114 | + |
| 115 | +AI工程化 |
| 116 | + |
| 117 | +向上滑动看下一个 |
| 118 | + |
| 119 | + |
| 120 | + |
| 121 | +AI工程化 |
0 commit comments