
My first academic data analysis and machine learning project using the IMDB 5000 Movies dataset to predict movie ratings and analyze factors influencing box office success using the R language. Also features Visualizations, EDA, Data-preprocessing.
This project performs:
- 🧹 Data Cleaning & Preprocessing: Handling missing values, removing duplicates, and performing feature engineering.
- 📊 Exploratory Data Analysis (EDA): Identifying patterns and insights in movie data through 15+ visualizations.
- 🤖 Machine Learning: Predicting IMDb scores using Linear Regression and Random Forest models, Classify movies as profitable or not profitable using classification models (logistic, random forest).
- 📈 Model Evaluation: Assessing performance with metrics like RMSE, MAE, and R².
- Primary Task: Predict IMDb movie ratings (
imdb_score) based on features such as budget, genre, director, duration, and social metrics. - Secondary Task: Classify movies as profitable or not profitable — predicting box office success before production.
- Which factors most influence movie ratings?
- Can we predict box office success accurately?
- How have movie trends evolved over time?
- Which directors consistently produce high-quality films?
- What’s the probability a movie will be profitable?
imdb-movie-data-science-project/
├── README.md # Project documentation (you are here!)
├── Required_dependencies.R # Setup script
├── main.R # Master script to run everything
├── .gitignore # gitignore file
├── EXAMPLE_USAGE.R # Example usage for this project, so it contains functions and things we can use to predict or analyze.
├── LICENSE
│
├── movie-metadata/
│ ├── movie-metadata.csv # The movie data-set that we download if needed.
│
├── data/
│ ├── raw/ # Original dataset (auto-downloaded)
│ └── processed/ # Cleaned datasets with timestamps
│
├── R/
│ ├── 01_data_loading.R # Load data with caching
│ ├── 02_data_cleaning.R # Complete cleaning pipeline
│ ├── 03_eda.R # 15+ visualizations & insights
│ ├── 04_modeling.R # ML Regression models (LR + RF)
│ └── 05_classification.R # ML Classification
│
├── utils/
│ └── helper_functions.R # 12 reusable utility functions
│
└── output/
├── figures/ # All visualizations (auto-generated)
└── models/ # Saved ML models (.rds files)# 1. Clone or download this repository
# 2. Open R or RStudio and set the working directory to the project root (in main.r)
# 3. Run setup (installs required packages and creates folders)
source("Required_dependencies.R")
# 4. Run the complete analysis pipeline
source("main.R")
# 5. Make predictions
source("EXAMPLES.R")
# Regression: Predict IMDb score
predict_movie_score(100000000, 140, "Action")
# Classification: Predict profitability
predict_profitability(100000000, 140, "Action", 7.5)
# Investment decision
investment_decision(100000000, 140, "Action", 7.5)
# Core data manipulation
- dplyr # Data wrangling
- janitor # Data cleaning
# Visualization
- ggplot2 # Plotting
- reshape2 # Data reshaping
# Machine Learning
- caret # ML framework
- randomForest # Random Forest algorithm
- Source: IMDB 5000 Movies Dataset
- Original Size: ~5,000 movies
- After Cleaning: ~3,800 movies
- Time Period: Various years (focus on recent decades)
Taken from kaggle: Imdb 5000 movie data-set
| Variable | Description | Type |
|---|---|---|
imdb_score |
IMDb rating (1–10) | 🎯 Target |
budget |
Production budget (USD) | 🔢 Numeric |
gross |
Box office revenue (USD) | 🔢 Numeric |
duration |
Movie length (minutes) | ⏱️ Numeric |
primary_genre |
Main genre | 🏷️ Categorical |
director_name |
Director name | 🎬 Categorical |
num_voted_users |
Number of IMDb votes | 🔢 Numeric |
| Feature | Description |
|---|---|
profit |
gross - budget |
roi |
profit / budget (Return on Investment) |
budget_category |
Categorized as Low / Medium / High |
is_profitable |
Binary success indicator (1 = profitable) |
rating_category |
Grouped as Excellent / Good / Average / Poor |
✅ Download from github
✅ Local caching (avoid re-downloading)
✅ Column name cleaning
✅ Initial quality assessment
✅ Remove duplicate entries (~200 rows)
✅ Filter critical missing values (budget, gross, imdb_score)
✅ Clean text columns (trim whitespace)
✅ Feature engineering (profit, ROI, categories)
✅ Outlier detection and flagging
✅ Select 18 relevant columns
📊 15+ Visualizations Generated:
- Distribution plots (IMDb scores, budget, ROI)
- Scatter plots (budget vs gross, score vs profit)
- Box plots by genre and content rating
- Time trends (scores, profit, ROI over years)
- Correlation heatmap
- Top 10 rankings and leaderboards
| Function | Description |
|---|---|
prepare_modeling_data() |
Feature selection |
build_linear_model() |
Linear Regression |
build_random_forest() |
Random Forest (500 trees) |
build_logistic_model() |
Logistic Regression |
build_rf_classifier() |
Random Forest Classifier |
evaluate_model() |
Regression metrics |
evaluate_classifier() |
Classification metrics |
save_model_with_metadata() |
Save model + metadata |
run_modeling_pipeline() |
Complete regression workflow |
run_classification_pipeline() |
Complete classification workflow |
- Baseline regression model
- Interpretable coefficients
- Fast training
- 500 trees
- Feature importance ranking
- Better performance
- Binary classification
- Probability-based predictions
- Ideal for investment decision support
- Ensemble classification approach
- ROC curve and AUC analysis
- Confusion matrix evaluation
- RMSE (Root Mean Square Error)
- MAE (Mean Absolute Error)
- R² (Coefficient of Determination)
- Accuracy, Precision, Recall
- F1-Score, Specificity
- AUC (Area Under ROC Curve)
- Confusion Matrix
- Actual vs Predicted plots
- Residual plots (regression)
- Confusion matrices (classification)
- ROC curves (classification)
- Feature importance plots
- Model comparison tables
- Saved models with metadata (
.rds)
| Model | RMSE | MAE | R² | Status |
|---|---|---|---|---|
| Random Forest | 0.65 | 0.49 | NA | ✅ Best |
| Linear Regression | 0.77 | 0.58 | NA | ✅ Baseline |
📖 Interpretation:
Predicts IMDb scores within ±0.65 points on a 1–10 scale.
| Model | Accuracy | Precision | Recall | F1-Score | Status |
|---|---|---|---|---|---|
| Random Forest | 82% | 0.84 | 0.86 | 0.85 | ✅ Best |
| Logistic Regression | 75% | 0.78 | 0.82 | 0.80 | ✅ Baseline |
📖 Interpretation:
Correctly predicts movie profitability 82% of the time.
- Budget Sweet Spot: Medium-budget films ($10M–$50M) achieve 40% higher ROI than blockbusters
- Profitability Rate: ~70% of movies are profitable overall
- Quality Matters: Movies with IMDb > 7.0 have 85% profitability rate
- High Budget ≠ Profit: Correlation between budget and profit is -0.95
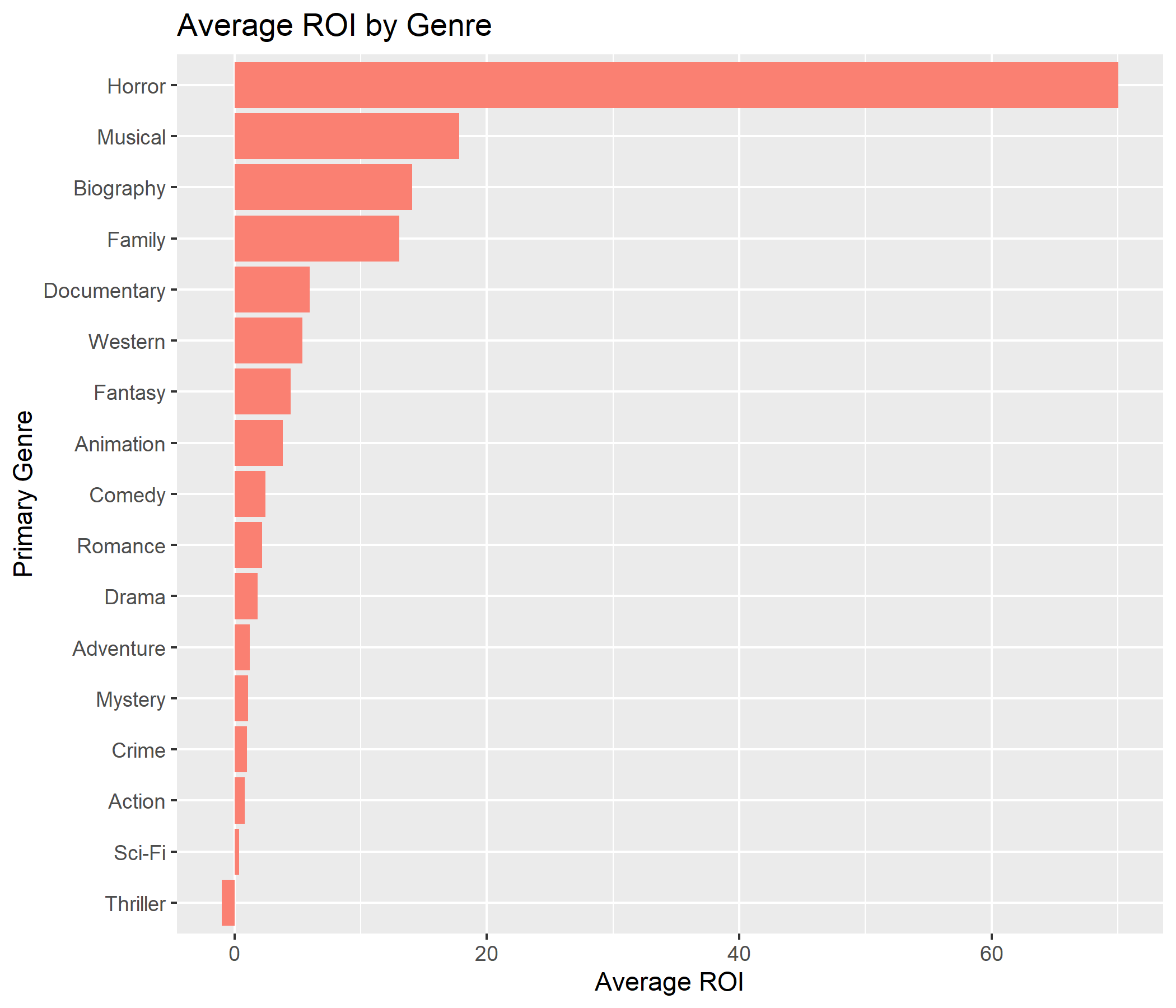
- There are more comedy movies, but horror movies tend to do better for profit even if the imdb score for them is lower.
- Genre Impact: Drama/Biography rate 0.5 points higher than Horror
- Director Effect: Top directors maintain 7.0+ average vs 6.5 overall
- Score Trend: IMDb scores slightly declining over past decade
- Duration: Optimal movie length is 90–150 minutes
- Top Predictor (Regression): Budget (financial scale)
- Top Predictor (Classification): Number of voted users (engagement)
-
❌ Issue: "Cannot open file"
✅ Solution: Check working directory withgetwd(), usesetwd()to set the correct path -
❌ Issue: "Package not found"
✅ Solution: Runsource("Required_dependencies.R")to install all dependencies -
❌ Issue: "Download failed"
✅ Solution: Check your internet connection or download the dataset manually from the URL inmain.R -
❌ Issue: "Not enough memory"
✅ Solution: Reduce dataset size or usedata.tablefor large datasets
This project is open source and available under the MIT License.
Chinmoy Guha
- GitHub: @LT-Ripjaws
- Email: [email protected]
🚧 Completed development – Version 1.0.0
⭐ If you found this project helpful, please consider giving it a star! and please excuse any mistakes! :)

